保姆级教程:零基础用VPS搭建私人AI大模型(Ollama+DeepSeek/Llama3)
引言
原本我也想偷个懒,让 AI 来帮我写这篇文章的引言。结果多试了几次,发现那种「千篇一律的完美开头」实在用不下去——一眼就能看出是 AI 写的,那种人味儿和真实体验瞬间没了。
既然这篇文章是讲「自建 AI 模型」,那干脆老老实实用人手写完,顺便聊聊我为什么选择自己在服务器上搭一个 AI 模型助手,以及整个搭建过程到底有多 easy 。
一、为什么要自己搭建 AI?
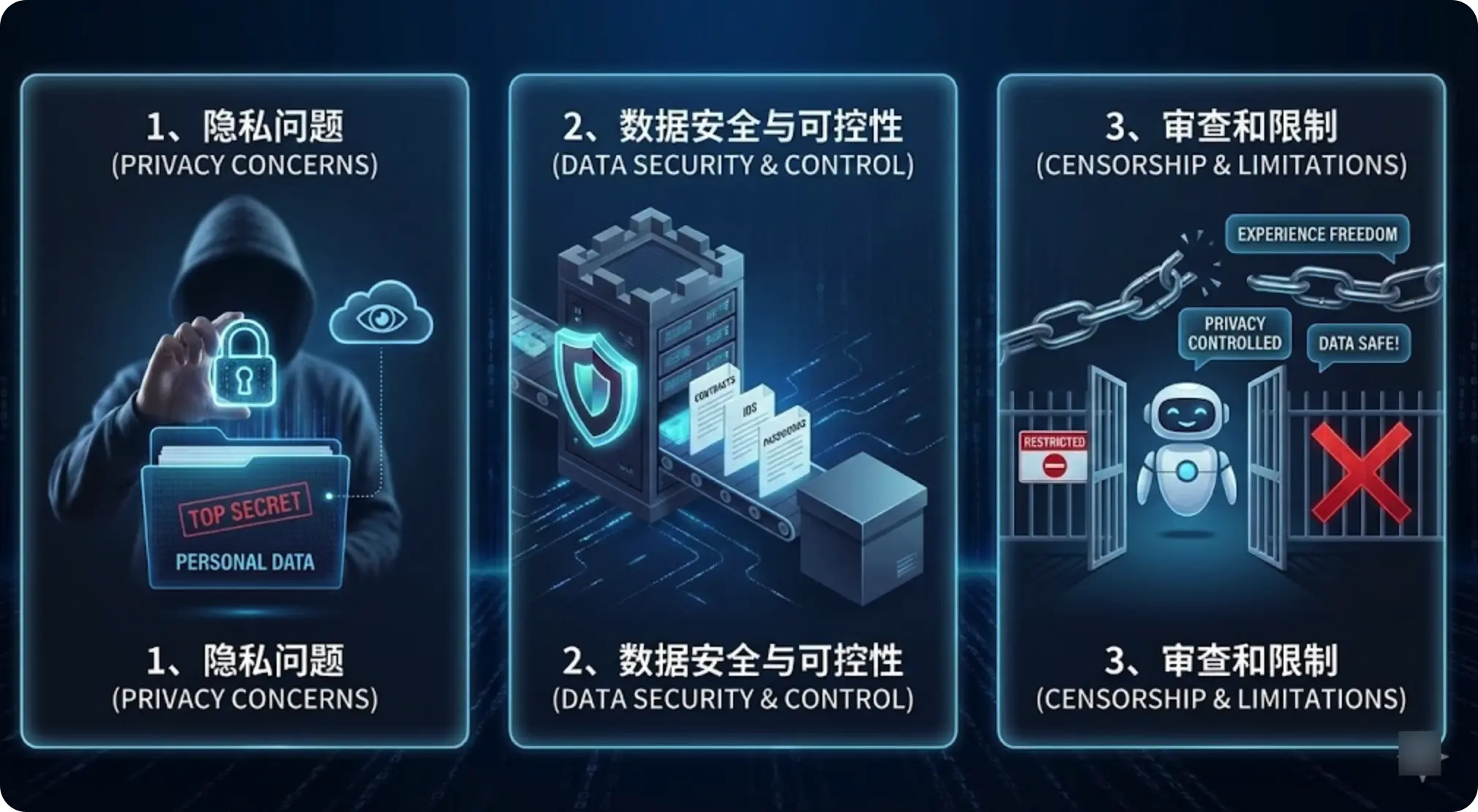
现在几乎人人都在用 AI:写文案、写代码、查资料、总结报告……
我自己写博客、折腾 VPS 的时候,也经常把问题丢给 AI 处理。
但有几点,我始终不太放心:
1、隐私问题
公开放在网上的内容,用在线 AI 处理当然没什么问题。但一旦涉及这些东西,我基本不会用云端 AI:
- 合同条款、公司内部文档
- 身份证、护照等个人信息
- 带有账号密码、服务器信息的配置
再怎么承诺「严格保护隐私」,从技术上讲,这些服务商完全有能力访问你的输入数据,更不用说这些数据未来是否会被用于训练下一代模型。
2、数据安全与可控性
很多大模型服务都明确写着: 你在产品中输入的内容,可能会被用于优化模型。
对普通闲聊来说无所谓,但如果是你的业务逻辑、数据结构、客户信息,被拿去训练模型,心里多少会有点膈应。
3、审查和限制
公有云上的 AI 通常都会带有比较严格的内容审核。很多时候你只是想了解一些「边缘但不违法」的知识,比如:
- 一些医学、隐私相关的话题
- 某些网络安全的原理性内容
很多国内 AI 会直接来一句「作为一个 AI 语言模型,我不能……」,顺便给你上一堂道德课。
自建模型的好处是:你可以自己决定边界。模型本身可能依然有一些基础安全限制,但整体来说不再受平台风控和审查策略的影响——当然,这也意味着你自己要对使用结果负责。
总之,自建 AI 的核心原因就三点:
体验更自由、隐私可控、数据安全!
二、自建 AI 模型对电脑或服务器配置要求
要在自己的电脑或服务器上流畅的运行 AI 模型,你的电脑或服务器的配置不能太低。如果你想要在你的个人电脑上安装,那么至少我个人建议他必须要有一张还算过得去的显卡,因为你要知道如果电脑配置太低的话,这些AI生成的内容会特别特别的慢,有时候几秒钟才能输出一个文字。
这里给出一些基本的建议:
1. 在本地电脑上跑(Windows / macOS)
Windows 建议:
- 显卡:建议至少 GTX 960 / GTX 1060 这一级别往上
- 内存:16G 起步更舒服
- 硬盘:留出几十 G 给模型
如果显卡太老、显存太小,模型也不是跑不了,只是输出速度可能慢到你怀疑人生。
macOS 建议:
- 芯片:Apple Silicon(M 系列)
- 内存:16G 比 8G 更稳,尤其是你要跑 8B 模型的话
- 同样需要准备几十 G 硬盘空间
M 系列的 NPU / GPU 对这类任务还挺友好,日常体验比很多老台式机要好。
2. 在 VPS / 服务器上跑(无 GPU 场景)
如果你不想占用自己的电脑资源,那么在云服务器运行 AI模型 是很好的方案。
以我自己的例子:
我用的是 netcup 的 RS 1000 G12,配置是:
- 4 核 CPU
- 8G 内存
- 256G SSD
最低推荐配置(无 GPU):
- CPU:4 核起步(2 核也能跑,但体验偏差)
- 内存:8G 更合适,4G 只能跑非常小的模型
- 硬盘:至少预留 20–50G 空间给模型(多个模型的话还要更多)
三、自建 AI 模型需要提前了解的事情
起初我以为 「自建 AI 模型 」,是一件非常繁琐的事情。直到我在查阅了大量资料以及实际操作过后发现其实特别的简单,整个过程其实就相当于在你电脑上或手机上多装了一个稍微吃配置的软件,你需要做的大概是这些:
- 安装一个叫 Ollama 的「模型管理器」
- 用几条命令下载你想要的模型
- 用命令行或者 Web 界面连上去聊天
整个流程比想象中简单得多,大概也就是三五条命令的事情。
四、Ollama 是什么?为什么选择它?

关于 ollama!它是启动大型语言模型(如 gpt-oss、Gemma 3、DeepSeek-R1、Qwen3 等)最简单的方法。他就像一个手机的应用市场,你需要的各种模型都可以通过它来下载使用。
ollama 支持 Windows、macOS、以及 Linux 三个平台。
Ollama 官方主页:https://ollama.com
Ollama 下载:https://ollama.com/download
Ollama 官方 GitHub 源代码仓库:https://github.com/ollama/ollama/
五、热门自建 AI 模型都有哪些?

你可以在 模型 找到当前 Ollama 支持的所有 AI 模型。这个页面上他会实时显示当前最新所支持的模型以及这些模型更新的时间。也可以看到哪些模型下载的人数比较多。可以看到当前 Deepseek 下载量还是很大的。
这里以表格的方式总结了一下,截止博客发布时比较热门的AI模型:
| 公司 / 机构 | 代表模型(开源/开放权重) | 简要定位 |
|---|
| Meta(Facebook) | Llama 3.1 / Llama 3.3 / Llama 4 | 全球影响力最大的开源通用模型生态;性能稳、社区强。 |
| 阿里巴巴 / 通义(Qwen) | Qwen3、Qwen2.5、Qwen3-VL、Qwen-Coder | 中文表现优秀,全能型;多模态和代码能力突出。 |
| DeepSeek | DeepSeek-R1、DeepSeek-V3、DeepSeek-Coder | 高推理能力,性价比极高;国内外都很受欢迎。 |
| Mistral AI(欧洲) | Mistral Large、Mistral Small、Mixtral | 轻量高效、性能稳,适合企业级应用。 |
| 微软(Microsoft) | Phi-4、Phi-4-mini、Phi 系列 | 小模型天花板;适合本地部署、边缘设备。 |
| Google / Google DeepMind | Gemma2、Gemma3、Gemma-Vision、Embedding Gemma | 高效易用,单卡可跑;多模态能力强。 |
| 智谱 AI(ZhipuAI) | GLM-4 / GLM-4.6 | 中文场景下表现优秀,推理与对话能力均衡。 |
| OpenAI(开放权重) | GPT-OSS、GPT-OSS-Safeguard | 面向开发者的开放权重模型,偏推理与工具调用。 |
关于模型中的 b 代表什么意思
不知道大家有没有发现,在每个模型的参数后面都有个类似 2b、3b、4b、8b 这些,你们知道这是什么意思吗?简单来说,这些数字后面的 b 代表 “Billion”(十亿),指的是模型中参数(Parameters)的数量。

你可以把“参数”想象成大脑中的“神经元”连接。
- 0.6b = 6 亿参数(相当于极其精简的“迷你脑”)
- 8b = 80 亿参数(标准的“笔记本电脑级”模型)
- 235b = 2350 亿参数(超级巨无霸,相当于服务器集群级的“超级脑”)
对于你的 VPS(无 GPU,纯 CPU)来说,这个数字直接决定了三个关键指标:智力、内存占用、运行速度。
| 尾缀 (参数量) | 智力 / 逻辑能力 | 所需内存 (RAM) | CPU 运行速度 | 适用场景 |
| 0.6b / 1.7b | 低 (甚至有点笨) | 极低 (1-2 GB) | 飞快 (每秒几十个字) | 简单的翻译、分类、或者是配置极低的设备。 |
| 4b | 中等 | 低 (3-4 GB) | 流畅 (每秒 5-10 字) | 你的 VPS 最佳选择。日常对话、简单问答。 |
| 8b | 良好 (主流水平) | 中 (6-8 GB) | 慢 (每秒 1-3 字) | 你刚才试过的就是这个。在纯 CPU 上很吃力。 |
| 14b / 32b | 非常强 | 高 (10-24 GB) | 龟速 (不可用) | 需要高端显卡。 |
| 235b | 顶尖 (GPT-4 级别) | 巨高 (140GB+) | 无法运行 | 除非你的 VPS 有 200GB 以上内存,否则跑不起来。 |
在一般家用电脑或者配置还不错的 vps上,一般来说选择 8b 模型是比较理想的,如果你的电脑或vps配置较低,那么只能选择4b或者更低的 0.6b/1.7b,总之配置越低,b越小。之后你可以根据实际输出效果来更改所选的模型参数(b)。
六、使用 Ollama 部署 AI模型的步骤
因 Windows 和 macOS 的安装过于简单,所以下面重点讲在云服务器(Linux)上安装、跑起来的全过程。
那么接下来我就在我之前购买的一台 4核 8G 的服务器上搭建这个自建的AI模型。
我准备的服务器来自 Netcup Root Server RS 1000 G12,每月 8.74 欧元。
- 系统:Ubuntu 24.04 / Debian 13(其它主流发行版类似)
- 环境:无 GPU,仅 CPU
- 目标:在 VPS 上跑一个 4b/8b 模型,当成自己的远程 AI 模型助手
1. 更新系统并安装基础工具
# 更新系统
sudo apt update && sudo apt upgrade -y
# 安装常用工具(curl、git 等)
sudo apt install -y curl git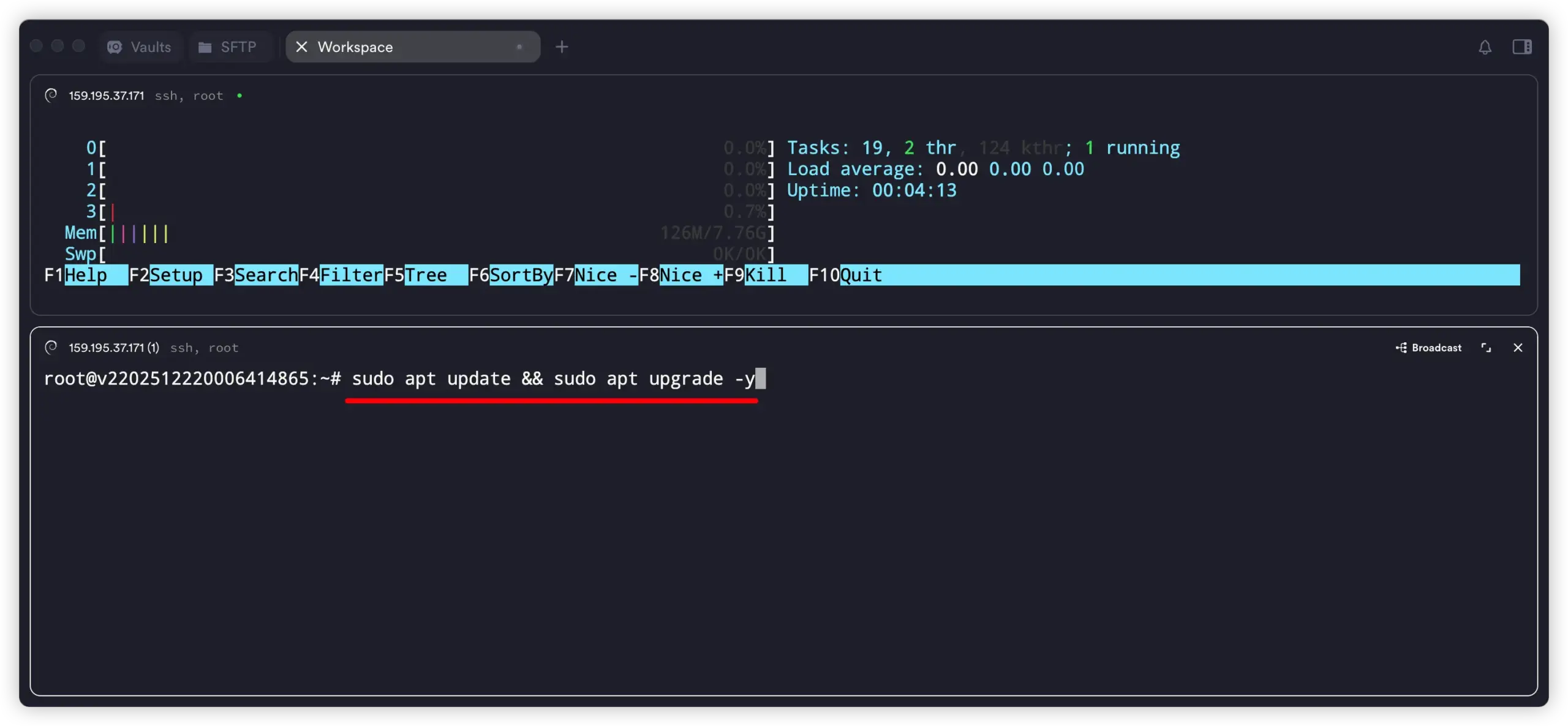
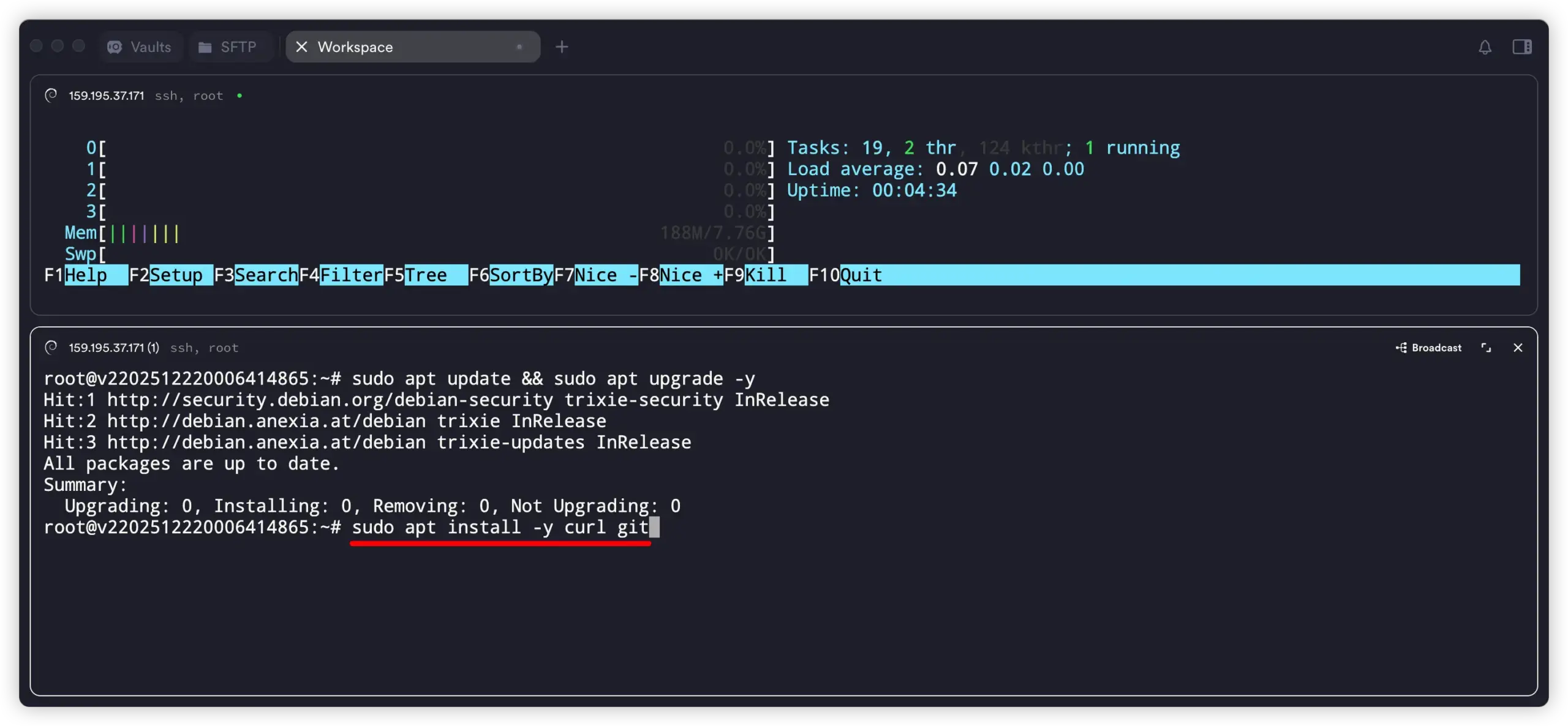
2. 一条命令安装 Ollama
官方给出的快速安装命令是:Ollama 文档
curl -fsSL https://ollama.com/install.sh | sh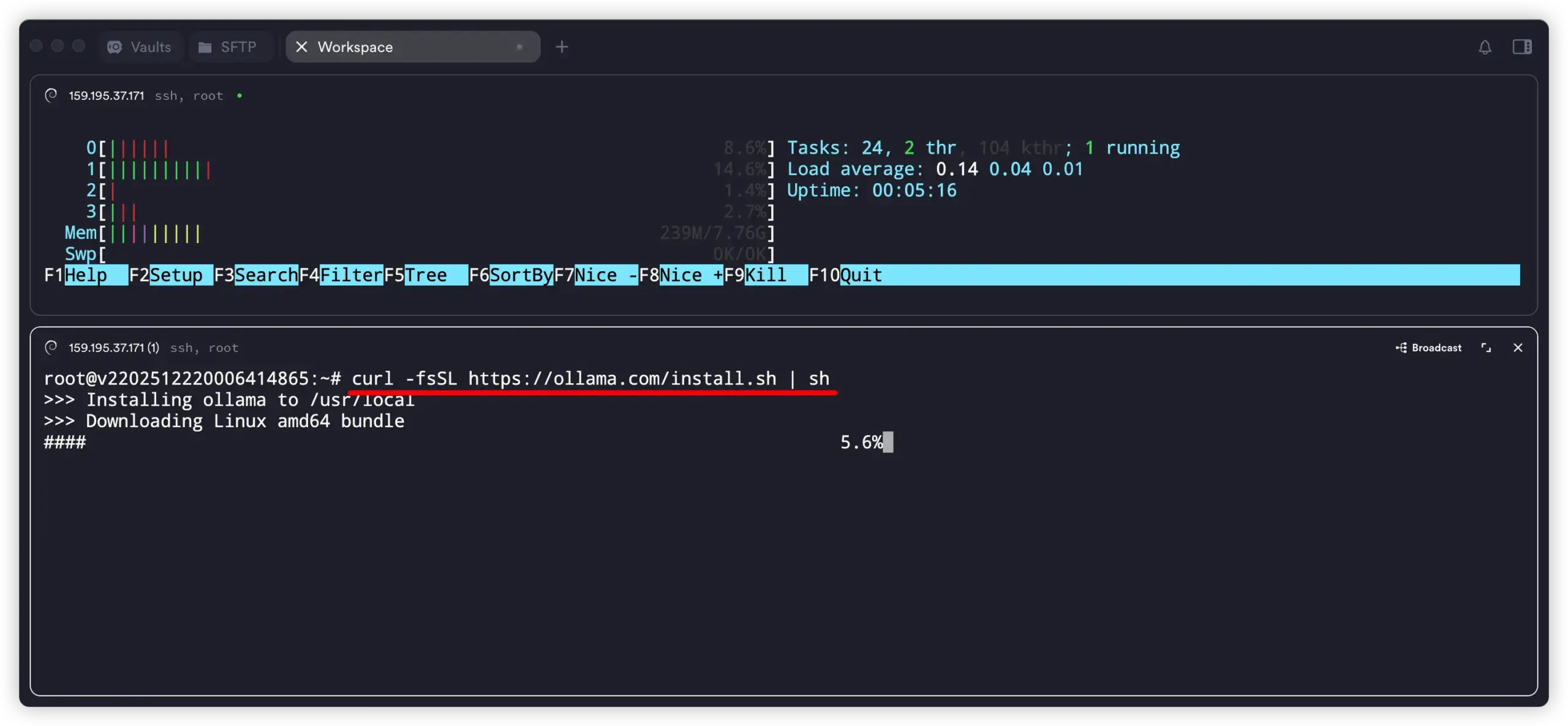
安装完成后,可以验证一下:
ollama -v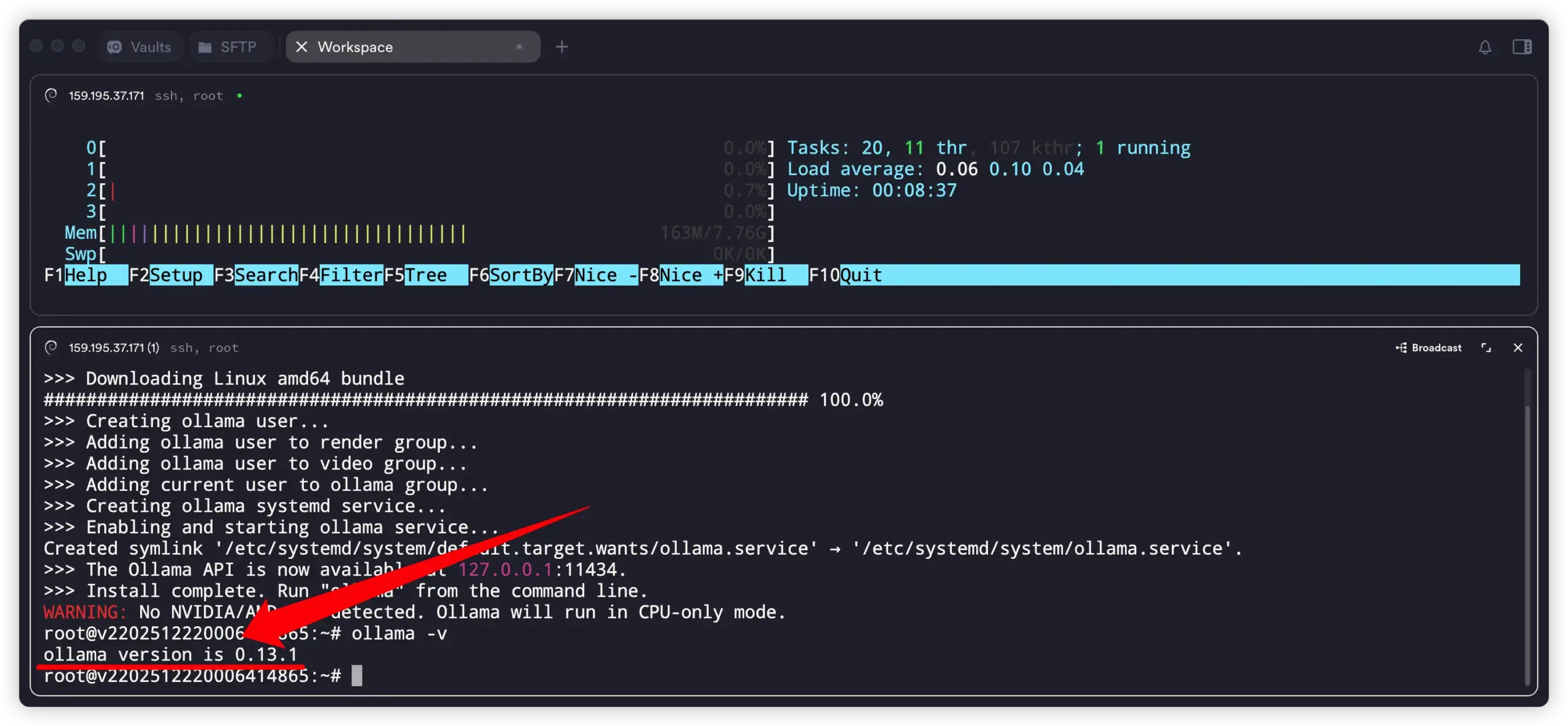
看到版本号说明安装成功。
小提示:如果你之前装过旧版本,官方建议先删除旧的
/usr/lib/ollama目录再重新安装。Ollama 文档
3. 启动 Ollama 服务
ollama serve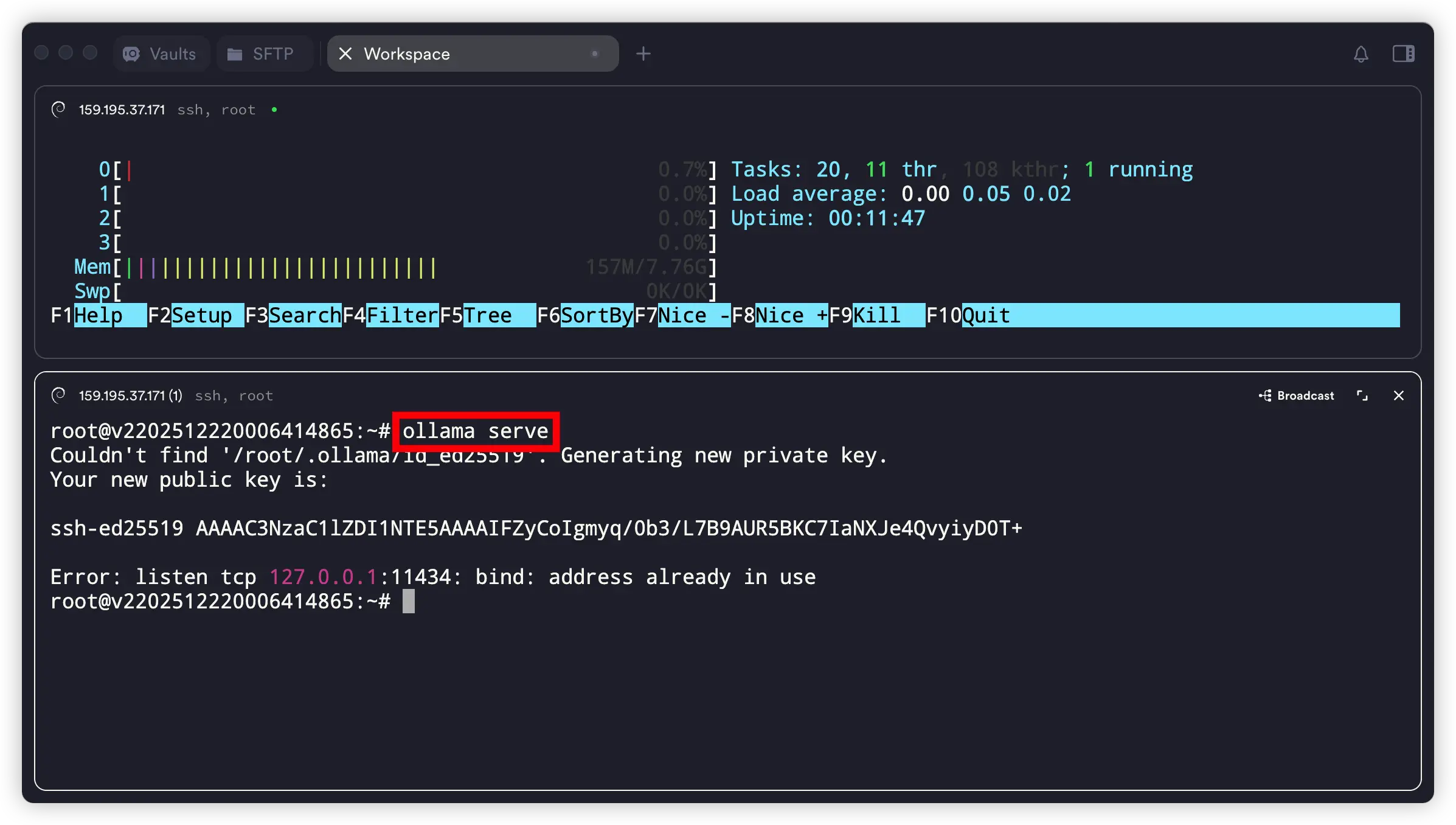
这个命令会在后台启动一个本地推理服务,默认监听在 127.0.0.1:11434 端口。
4. 运行一个你想用的模型
比如你想用 DeepSeek-R1 的 8b 模型,或者其它你在模型库里看到的模型,命令通常是这样的:参考:deepseek-r1
ollama run deepseek-r1:8b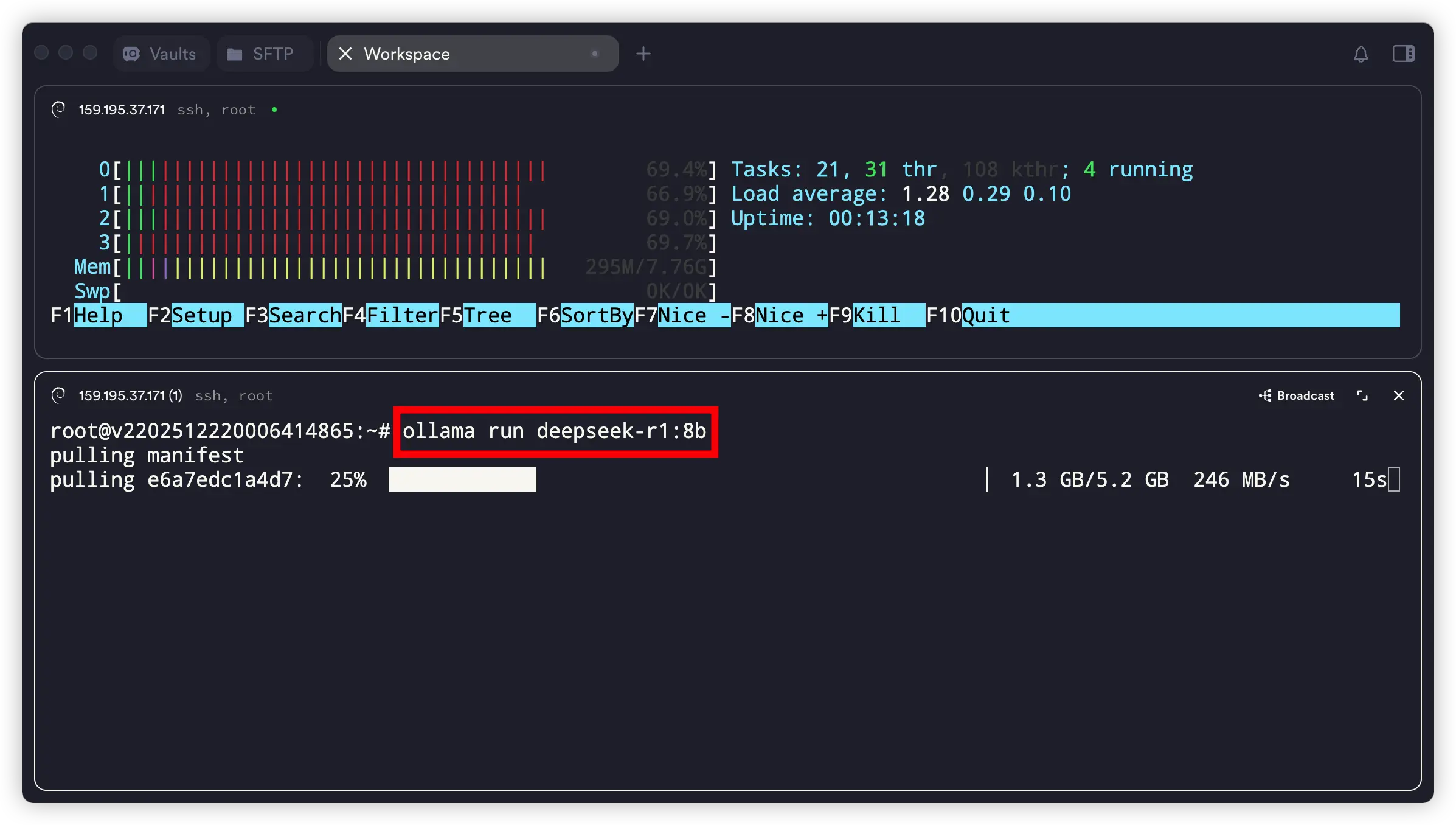
真快!
5.2G 的 DeepSeek-R1 的 8b 模型,仅在数秒内下载完成。网络速度 246MB/s,不是一般的快!
具体可用的模型名字、参数量,可以在官方模型库里直接查到:
https://ollama.com/library Ollama
5. 在命令行里测试效果
>>> 请介绍一下你自己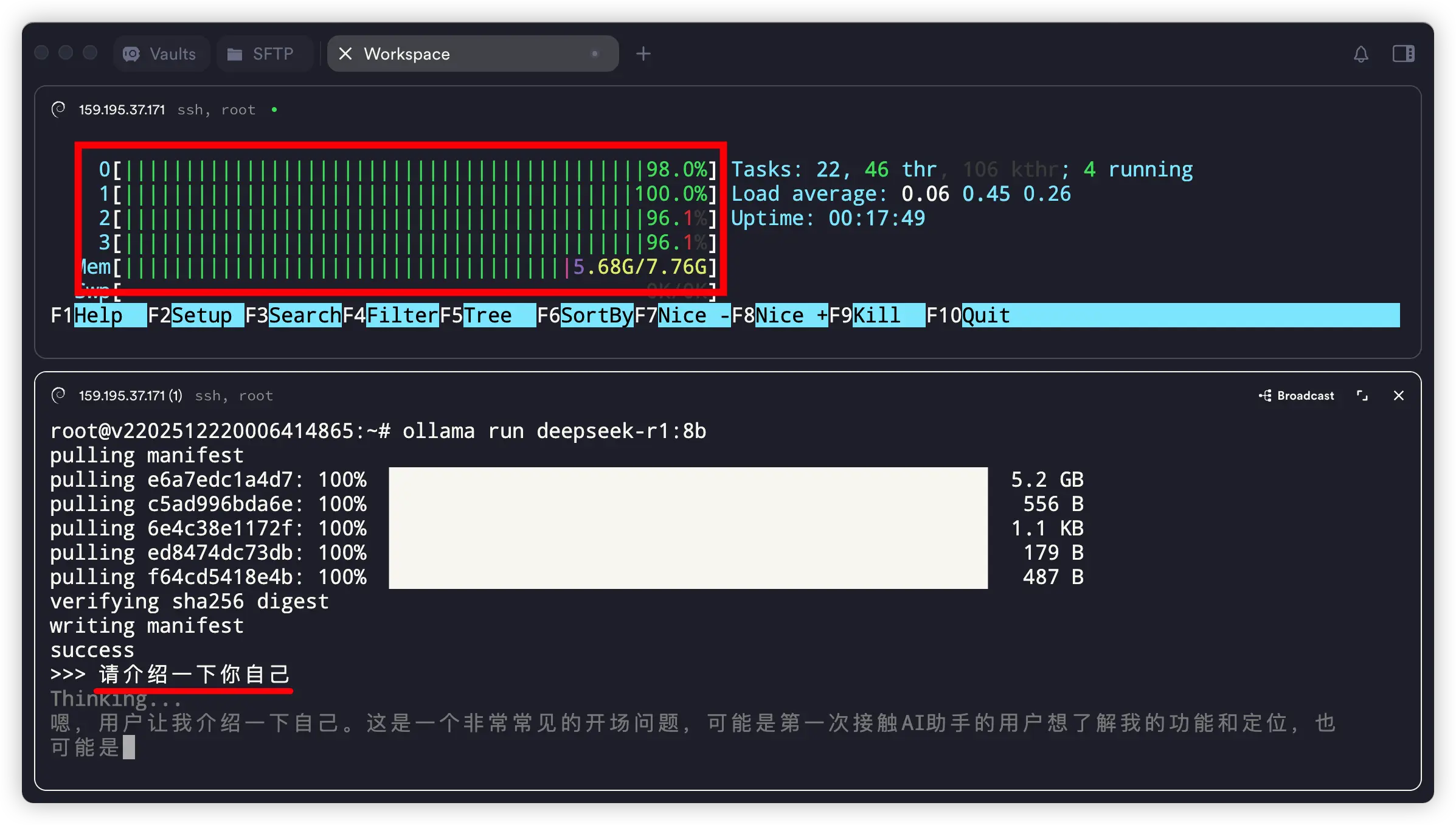
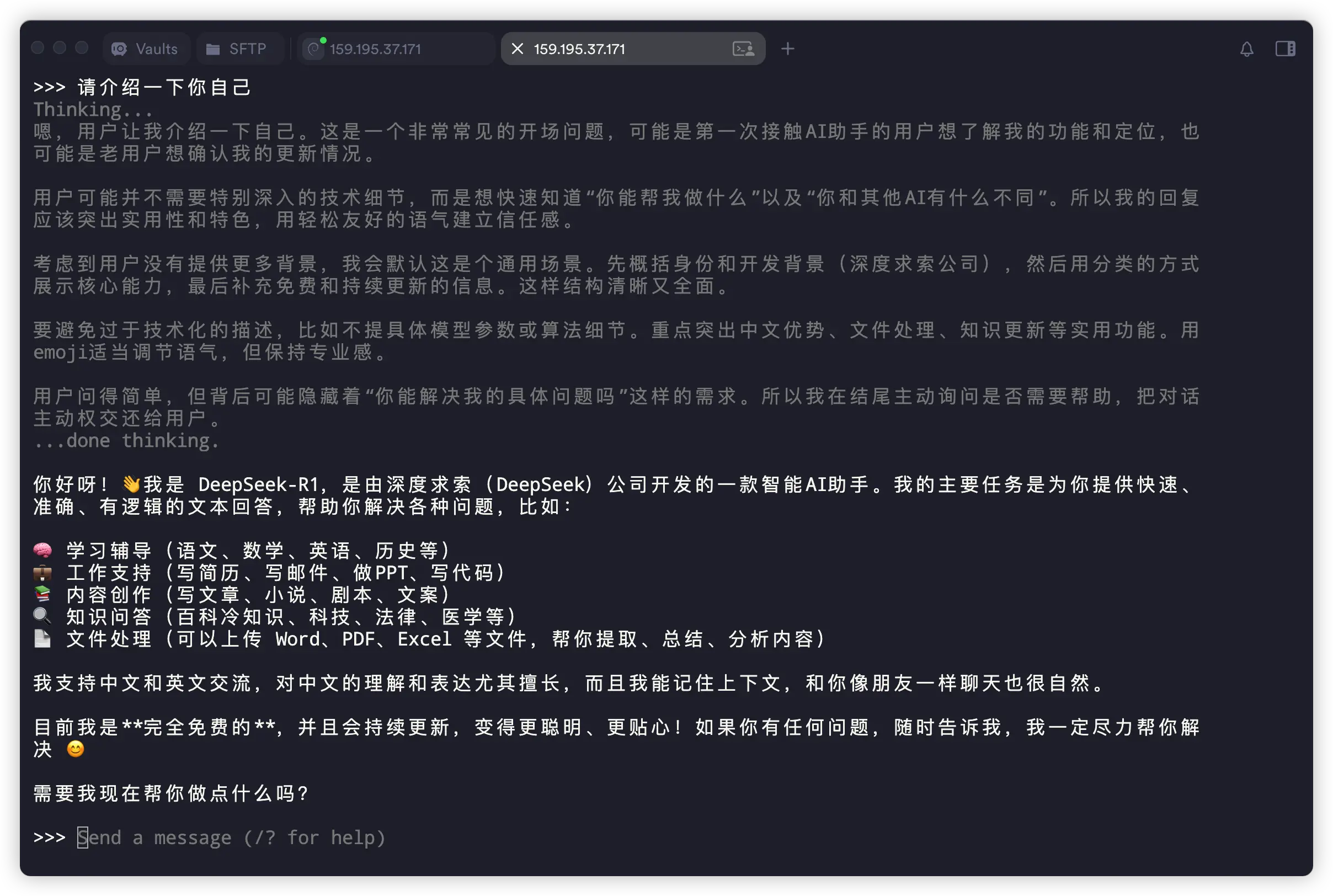
执行后会进入一个交互界面,直接开始跟它聊天即可。快捷键 Ctrl + D 或输入 “/bye” 可退出。
在这台服务器上,运行这个 8b 的 AI模型,回答的速度还挺快!
CPU和内存占用几乎占满
上图可以看到,在这台 4核8G内存的服务上运行 DeepSeek-R1 的 8b 模型时,CPU 几乎满载运行,内存也占用了将近 75%。可见运行 AI 模型有多耗性能!
6. 切换其它模型
如果你想体验其它 AI模型,抑或是觉得自己设备配置较低,输出速度太慢,想换其他的模型,可以直接用 快捷键 Ctrl + D 或输入 “/bye” 退出当前对话,然后使用命令:ollama run + 模型名称。
这里以阿里的 qwen3 为例,这次我运行:
ollama run qwen3:4b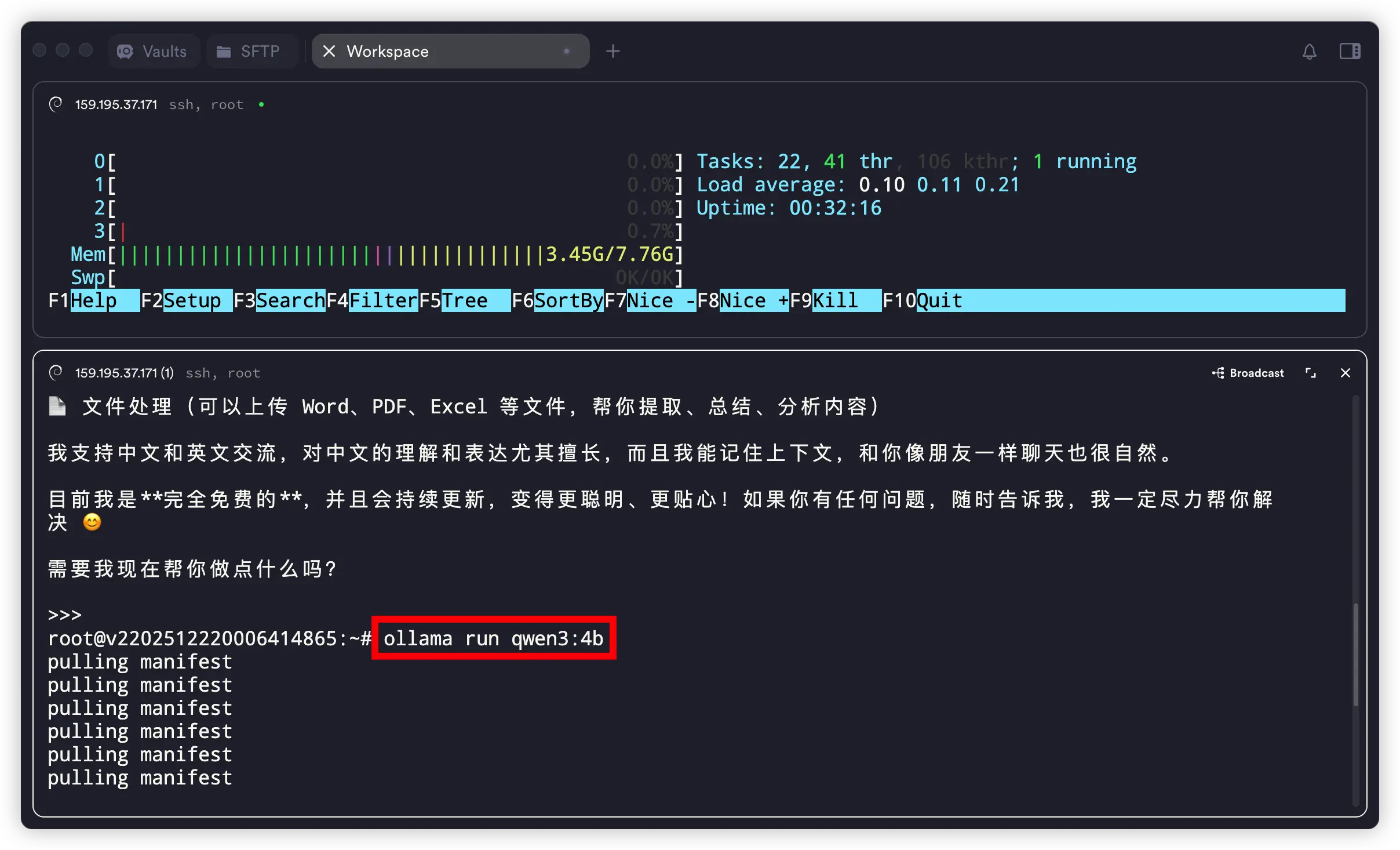
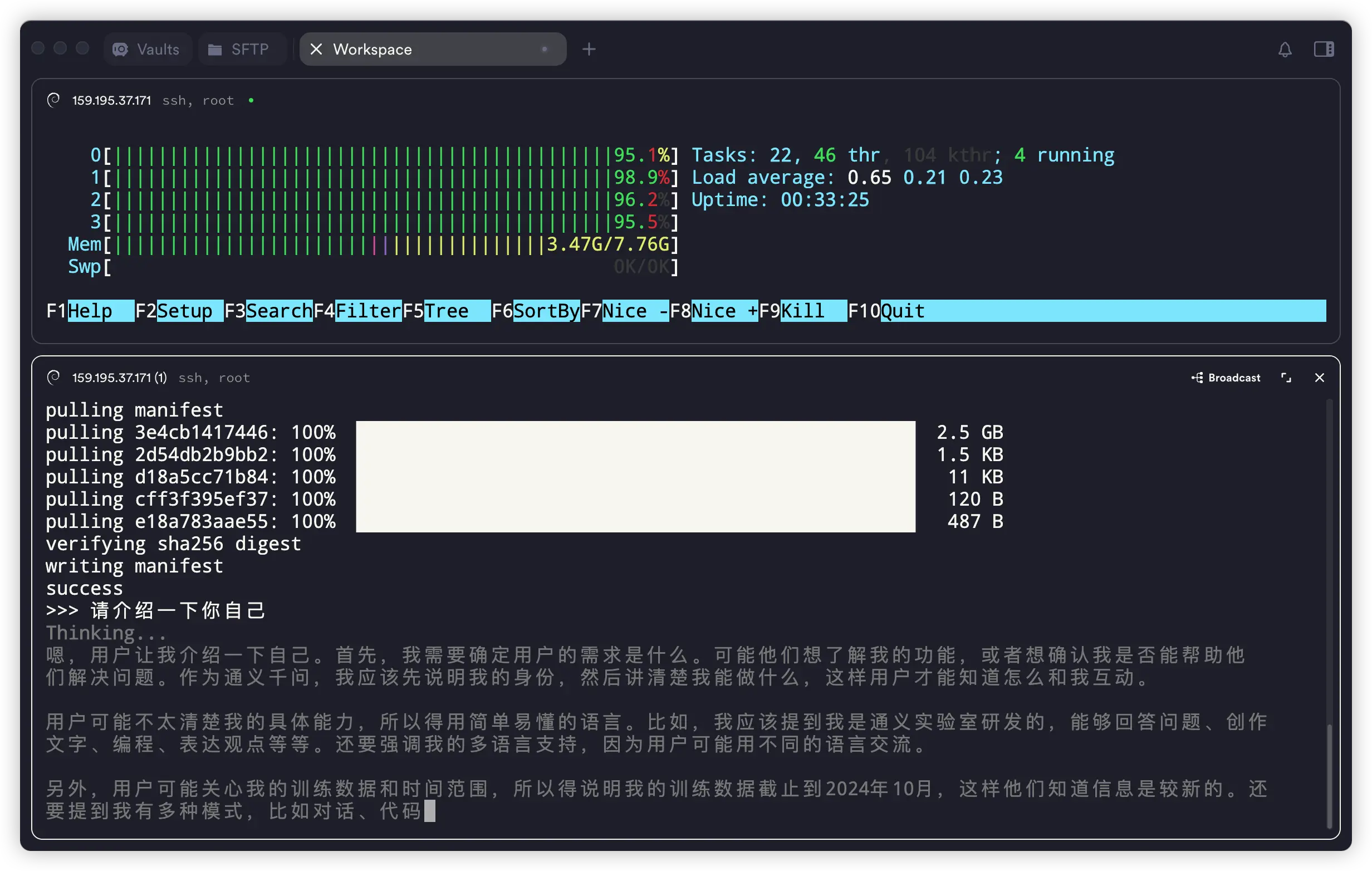
这个模型相比上面的 8b,肯定是打不过的,但是它可以更快的输出速度。
七、使用浏览器访问
命令窗口终究不够方便,使用浏览器的话就可以不受限制地访问。网络上也有很多开源的前端面板,可直接通过浏览器来完成各项对话操作。
其中比较出名的是 Open WebUI,这是该项目的GitHub仓库地址:https://github.com/open-webui/open-webui。
搭建 Open WebUI 最简单的方式使用 docker,想要使用该工具,需要现在服务器上安装 docker。
1、使用官方一键脚本安装 docker
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh ./get-docker.sh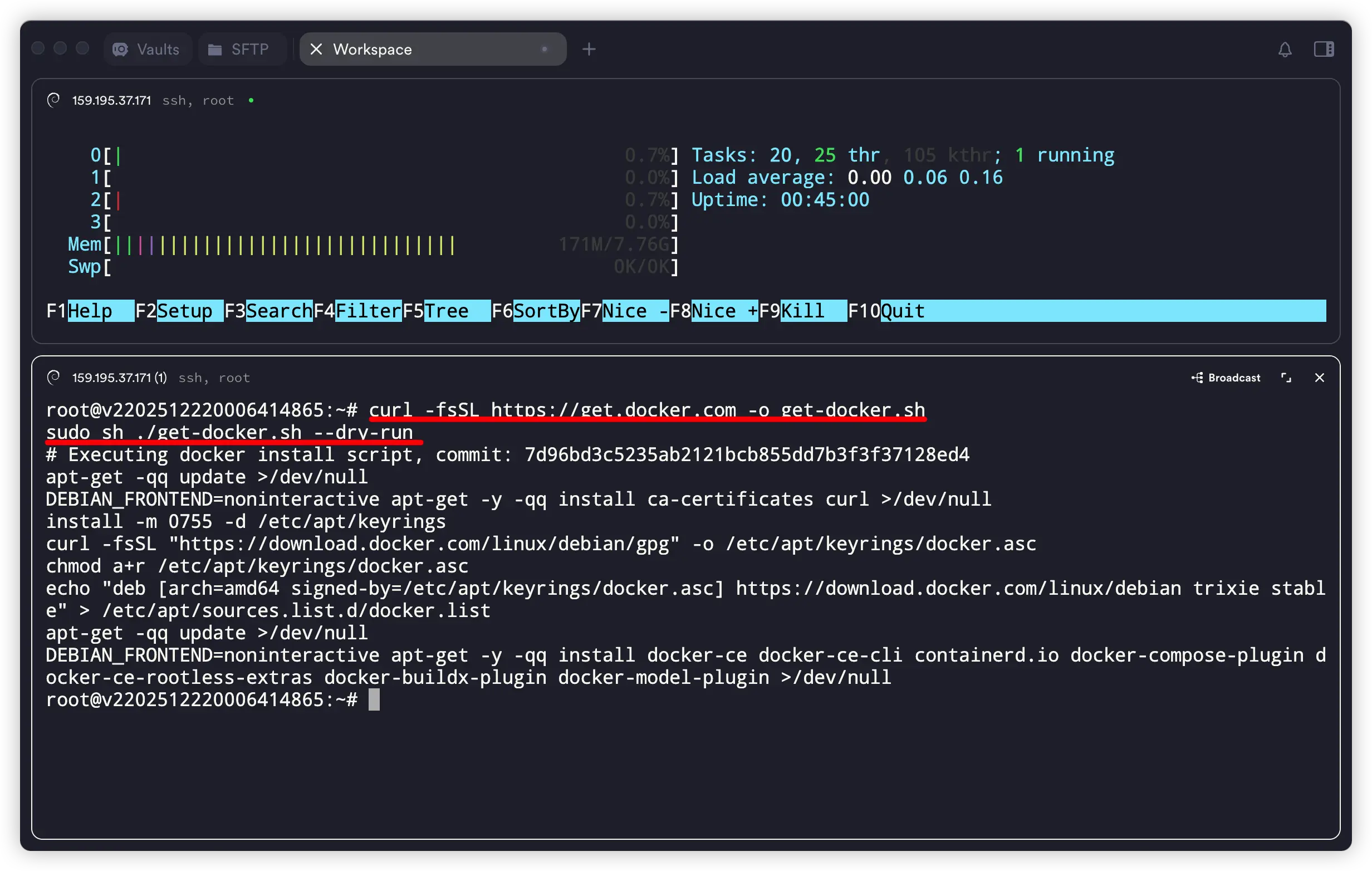
2、使用 docker 命令安装 open-webui
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
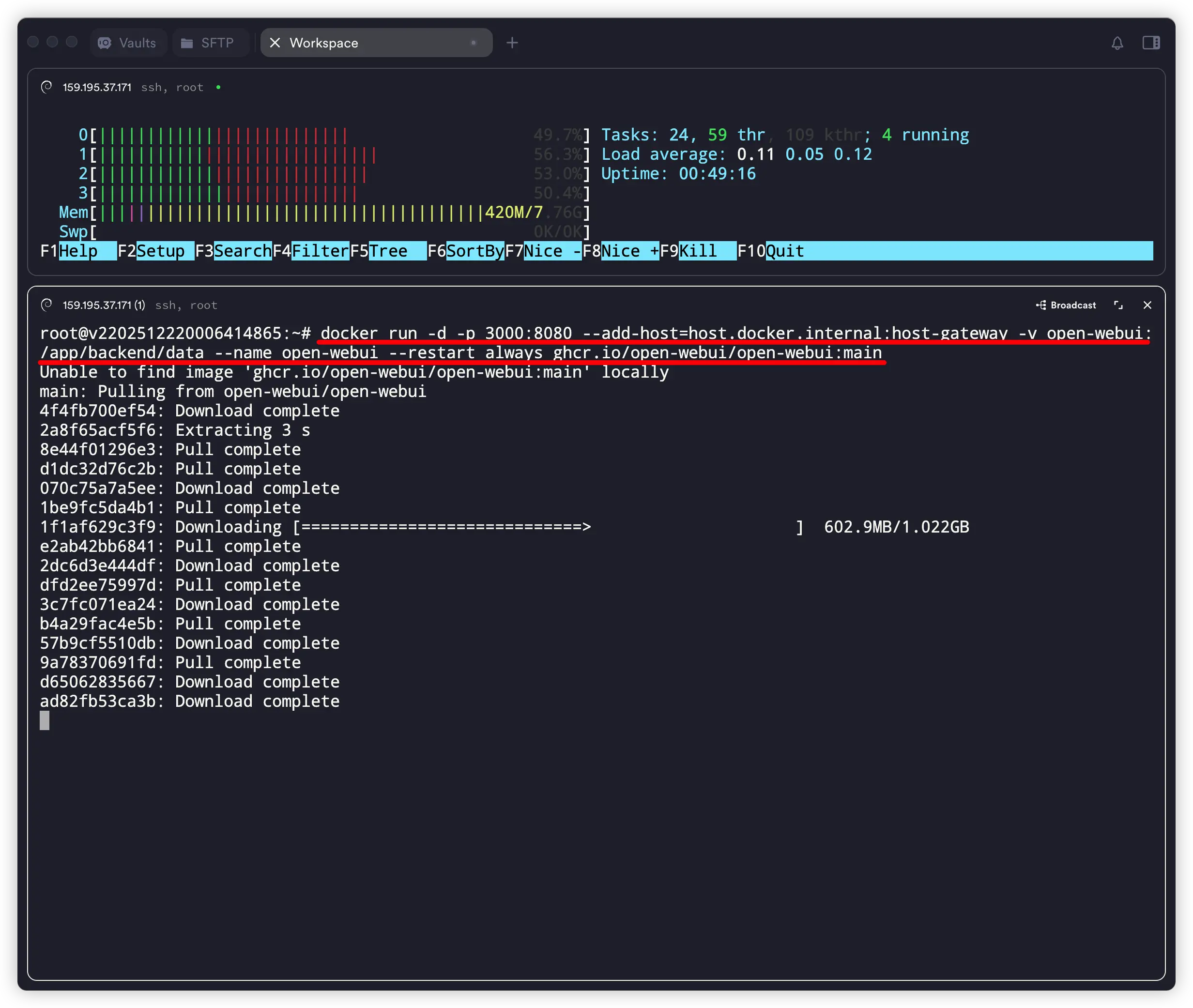
输入命令:docker ps ,查询open-webui 运行情况。在 STATUS 中出现 “Up ….” 即代表运行成功。

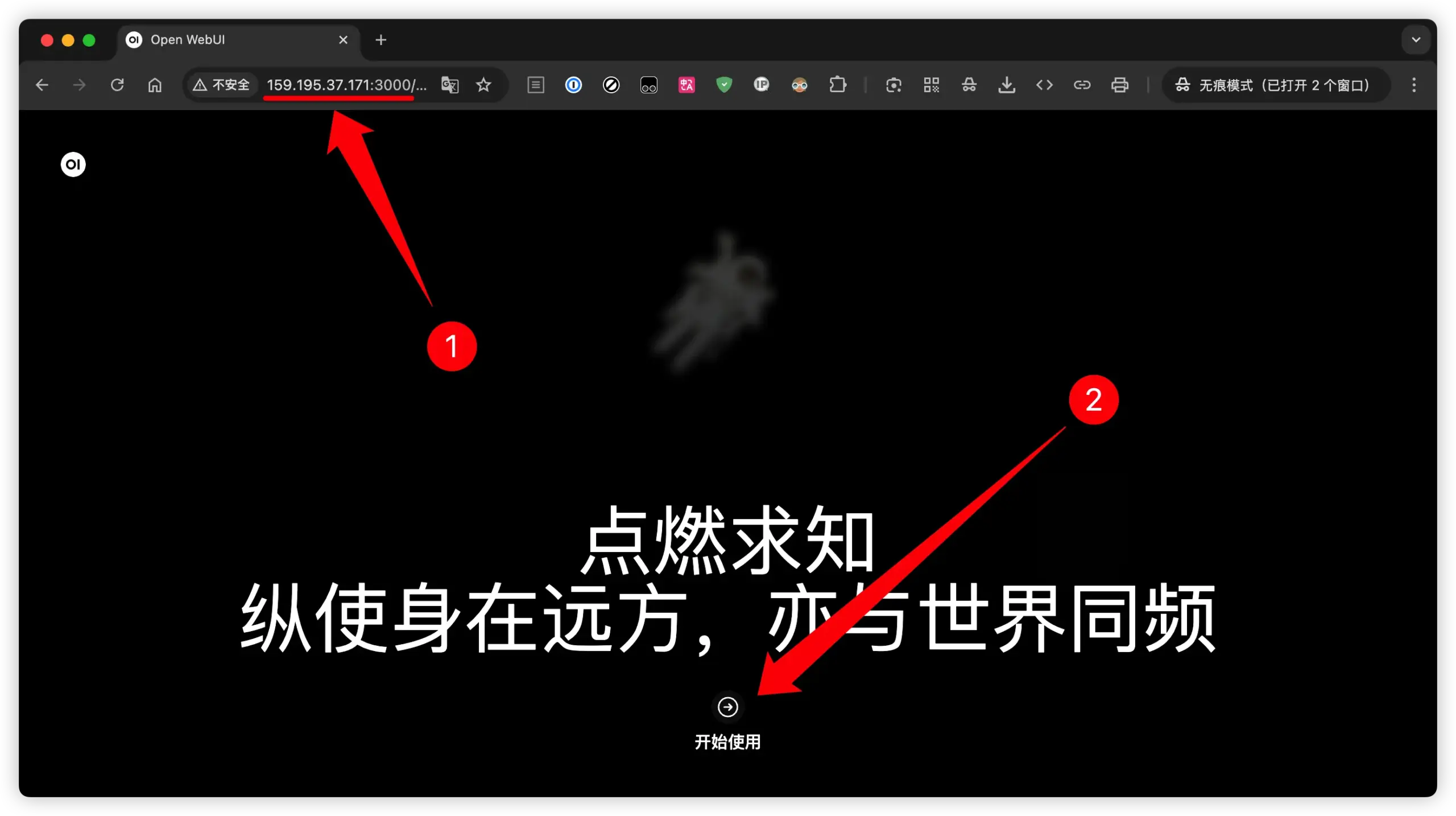
3、使用浏览器访问
在浏览器地址栏输入 “IP + 端口号:3000”,例如示例中的:http://159.195.37.171:3000/,此时可能会弹出不安全的网页提示,我们选择继续访问。就会打开创建管理员的页面。
4、创建管理员
输入名称、电子邮件和密码,点击 “创建管理员账号” 。

5、open-webui 搭建成功
6、配置 Ollama 允许外部连接
上面虽然搭建成功了,但是在左上角选择模型中并没有任何的模型,此时我们需要 “设置 OLLAMA_HOST 环境变量为 0.0.0.0,这样 Ollama 才会监听所有网络接口,包括 Docker 容器的请求。”
第一步:直接写入配置
复制下面的整个代码块(包括 echo 和 tee 的部分),在终端粘贴并运行:codeBash
sudo mkdir -p /etc/systemd/system/ollama.service.d
echo '[Service]
Environment="OLLAMA_HOST=0.0.0.0"' | sudo tee /etc/systemd/system/ollama.service.d/override.conf(这条命令会直接创建需要的文件夹和文件,并写入配置,不需要手动打开 nano 或 vi 编辑器。)
第二步:重新加载并重启 Ollama
配置写入后,必须重启服务才能生效:codeBash
sudo systemctl daemon-reload
sudo systemctl restart ollama第三步:验证是否成功
你可以运行以下命令看配置是否已经生效:codeBash
systemctl show ollama | grep Environment如果看到输出里包含 Environment=OLLAMA_HOST=0.0.0.0,就说明成功了。
此时,你再去刷新 Open WebUI 的页面,应该就能连接上并看到模型了。

八、常见疑问解答
Q1:自建 AI 模型是否真的「绝对安全」?
A:不存在绝对安全,只能说相对安全。如果 AI 模型本身就不安全,那么你准备在安全的环境也无济于事。
Q2:一定要有显卡( GPU) 才能自建 AI 吗?
A:不是。
- 有 GPU:同样的模型会更快,可以跑更大的模型
- 没 GPU:也能跑,只是要选择 体量适合的模型(比如 4b / 8b),输出速度会慢一些
如果你只是写点博客、做做日常总结、处理一些中小段文本,纯 CPU + 4b / 8b 模型完全可以胜任。
Q3:自建 AI 会不会特别费流量?
A:自建 AI 的核心消耗在 算力(CPU)和硬盘,网络流量主要就是:
- 浏览器访问 Web UI 的流量(你自己的访问)
- 如果你在外网远程访问 VPS 的 Web 界面,也会有一定流量,但相对一般网站访问不算大
像这种只输出文本的 AI模型,不会特别费流量,生成视频、音频才费流量。
Q4:模型占多大硬盘?我需要准备多少空间?
A:不同模型体积差别很大,大致可以这么估:
- 迷你模型(1b 内):几百 MB ~ 1–2 GB
- 4b 级别:4–8 GB 左右
- 8b 级别:10–20 GB 左右
- 更大的模型,几十 G、上百 G 都非常正常
Q5:适合新手的模型怎么选?
A:如果你是第一次玩,可以先这样选:
- 追求推理能力:可以尝试 DeepSeek-R1 等思维链模型,但要接受「速度慢一点」的事实
- 中文 + 综合能力:Qwen 系列、DeepSeek 系列
- 英文 / 国际场景为主:Llama3 系列、Gemma 系列
- 配置一般:优先 4b / 7b 这个档位
九、总结
整个搭建过程很顺利,唯一的问题在于使用浏览器访问后等待的时间有点长,不如直接在命令窗口中的反应速度。
当前这个 4h8g 的服务器配置说实话,如果用在其它地方,这性能肯定绰绰有余,但 AI 是在是太耗性能,下次我将使用 netcup 的 RS 2000 G12 (8核16G)配置尝试。应该体验会更上一层楼。
免责声明: 本文基于个人经验分享,内容可能因时间、地区或个人情况而异。操作前请结合实际情况判断,必要时查询最新官方信息。如有疑问或建议,欢迎留言交流。




